
摩尔定律注定失效,存储优先架构或是AI芯片的未来
随着数据洪流时代的到来,AI技术应用的重要性日益凸显,而AI芯片的设计开发成为AI技术发展的关键一环。由于应对数据处理的优先级和方式不同,AI芯片所要面对的是海量数据处理。避免存储对于芯片时钟频率造成的拖累,跨越“存储墙”对于芯片性能提升的障碍已成为半导体行业广泛探讨的话题。而当“存储优先架构”(SFA)解决方案被提出来,我们似乎找到了开启未来AI芯片性能提升的金钥匙。
“存储墙”阻隔AI芯片性能大跨步提升
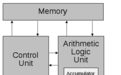
传统芯片的设计基于冯·诺依曼架构体系(如下图),是一种将程序指令存储器和数据存储器合并在一起的类PC设计概念结构。

冯·诺依曼架构体系
在这种相对传统的芯片设计思路中,计算模块和存储单元相互分离,数据从处理单元外的存储器提取,处理之后再返回存储器。以往我们的计算机应用场景下,这种架构能够较好的发挥频率优势,解决少量的复杂任务,并通过提高制程工艺不断提升频率达到芯片的性能提升。
而当我们面对数据洪流时代的AI场景时,包括深度学习神经网络、云计算、边缘计算等AI或AI相关场景中,与x86平台复杂运算相比计算任务往往是规模宏大的简单运算。由于冯·诺依曼架构的逻辑设计上,读取返回存储结构所消耗的时间巨大,大规模的数据计算会造成存储的读取和返回远跟不上芯片的频率,产生严重的延迟,成为芯片整体性能的瓶颈,这也就是现代应用场景下的“存储墙”的由来。

摩尔定律曲线已进入难以提升的“红区”
“存储墙”不仅造成了在大规模数据面前,芯片整体的性能下降,也进一步对于未来升级制程工艺提出更严峻的挑战。毕竟如今摩尔定律已经失效,在当前的技术工艺基础上,继续提升晶体管集成率缩小集成尺寸将会变得越来越困难。这会直接影响未来CPU、GPU、FPGA、ASIC性能的提升。可以毫不夸张地说,目前大部分针对AI、加速神经网络处理的研发创新,都是在与“存储墙”这个问题作斗争。
解决“存储墙”的思路和方式
既然“存储墙”问题在当下这个应用场景下需要被解决,就要有合理化的思路。针对跨越“存储墙”目前业界有几种优化思路,基本上都是围绕着更高、更快、更强几个维度,与咱们的奥运精神还挺像的。
硬性提升存储器的带宽和频率,这种方式其实目前沿用的传统性能提升方式之一。去年的AMD曾经在显卡的设计上采用了高带宽显存HBM就是一个思路类似的例子,通过提高带宽的方式提升存储器与GPU交流。虽然这能够在一定程度上带来GPU芯片效率的提升,但是这样处理也会对制造工艺提出新的要求,显然HBM比普通显存造价要更高、良率更低。而且虽然存储效率由于带宽增大实现了提升,但是转化到实际芯片的运算效率非常有限。这是一种优化之道,但并不能彻底跨越工艺限制的终极解决办法。

AMD为GPU做的HBM高带宽显存方案
动态调整频率则是通过软硬件动态调整存储器的读写频率,来降低访问调度的随机性,实现更多预访问,让访问变得更有序,进一步提升访问效率,进而降低延迟。此种手段实施并不简单,并且理论上提升的幅度十分有限,虽然可以一定程度上优化,但并不足以应付未来AI场景的百倍千倍数据吞吐,毕竟每小时TB级别海量数据才是AI世界的真实常态。
将存储结构尽量靠近核心,做成片上存储也是一种热门思路。精简的访问路径使得逻辑核心与存储的访问精度得到显著提升,尽可能利用工艺极限提升存储器的访问效率。这种方式的理论上可以在减少访问延迟5-10倍以上,这种量级的优化进步对比之前的几种方式就来得非常可观。
在思路和技术两个维度发现传统芯片的“存储墙”瓶颈之后,下一步就是从思想和技术两方面进行突破,这也就引出了我们今天的核心“存储优先架构”。
“存储优先架构”原理和优势所在
简单来理解,存储优先架构实际上就是片上存储技术+架构思想革新,是技术手段变革和思想革新的双重结合。
之前我们已经提到了片上存储这种设计方式的好处,它能够带来成倍的存储访问效率提升。但是片上存储这套思路实际上技术本身没有对架构思想进行变革,依旧是按照冯·诺依曼架构来的一套体系,虽然得益于片上存储技术,访问的效率大大提升了,但是由于架构不变,访问的步骤依旧较多,这带来了存储效率的浪费。
于是,在片上存储技术的基础上,探境科技提出了一种颠覆性的思想,以存储为中心带动计算,重新设计整个AI芯片的架构——即“存储优先架构”(SFA)。

探境科技提出的“存储优先架构”
上图是存储优先架构的示意图,通过对比冯·诺依曼架构示意图,我们从上图可以观察到存储架构包括数据层、计算层和控制层组成,它们以存储调度为核心逻辑形成一套计算架构,数据在存储之间的迁移过程中同时完成计算,计算就那么自然而然随着数据转移同时进行了。理论上这种设计方案的能效能提升10-100倍,计算资源利用率提升40-50%,同时对DDR的占用率也能够实现大幅度下降。这就好像从前城里10万老百姓办手续,不但路远,还要跑很多趟。现在百姓虽然已经多达500万,但是提高了办事效率,办事窗口离家门口更近了,还允许一次性办齐。
据了解,目前探境科技全新的存储优先架构并不仅仅只是停留在理论层面,而是真真正正已经流片,并即将推向商用领域。在今年10月份举行的IC WORLD大会上面,探境科技发布了即将推出的语音、图像序列AI芯片和IP授权。这些产品可以被用在AI计算、边缘计算、安放前端协处理、语音唤醒、命令词识别、语义理解、通用降噪、自动驾驶等多个前沿领域。
存储优先架构应用到实际能带来什么体验革新?举个例子:
目前智能音箱一个使用痛点就是语音控制和反馈的延迟。智能音箱需要听到用户的唤醒词进行唤醒,并在得到指令内容之后,将内容的声音数据回传到云端,进行分析和处理得到结果之后再返回到智能音箱播放出来。这中间由于信号、网络延迟等一系列问题就会导致最终用户体验质量的大幅下降,等待2、3秒也就成了常态。如果智能音箱采用存储优先架构的AI芯片,能够在本地接受内容之后直接处理为结果,不需要回传云端和大数据比对、分析和运算,实现高效的边缘计算,这将根本性提升最终的用户体验。智能音箱如是,自动驾驶如是,智慧新零售如是,智慧城市方方面面都离不开完整的AI、云计算、边缘计算的配合。
摩尔定律注定失效存储优先架构或是AI芯片的未来
从某种意义上来说,摩尔定律是基于冯·诺依曼架构提出的,而冯·诺依曼架构本身的结构路径基于指令集模式的处理逻辑,存在对于海量数据,尤其是不规则海量数据处理的先天短板。所以不管是摩尔定律和还是x86基础的冯·诺依曼架构,它们随着人类社会发展以及数据量的不断攀升,是注定必将失效的。或者反过来说,我们海量数据洪流的时代渐渐淘汰旧的芯片规则约束,正催生芯片架构进行一次大的革新。
存储优先架构以其逻辑步骤精简+片上存储技术手段的方式,得到双重性能提升,实现了以存储调度为核心的计算架构,这的确是一次前所未有的创新实践。随着探境科技流片量产和随后的应用场景部署,存储优先架构的AI芯片必将帮助终端设备实现更多自动化的、低延迟的边缘计算,以改善最终的智慧生活体验。关于存储优先架构的AI芯片产品以及未来的具体应用进展,我们不妨持续关注拭目以待。
免责声明:以上内容为本网站转自其它媒体或企业宣传文章,相关信息仅为传递更多信息之目的,不代表本网观点,亦不代表本网站赞同其观点或证实其内容的真实性。

