
金山云金睛神经网络监督方式多篇论文入选CVPR2019
2019年03月26日 10:08:22
来源:凤凰网商业

全球计算机视觉与模式识别顶级会议IEEE CVPR 2019(Conference on Computer Vision and Pattern Recognition)将于6月16日-20日在美国长
全球计算机视觉与模式识别顶级会议IEEE CVPR 2019(Conference on Computer Vision and Pattern Recognition)将于6月16日-20日在美国长滩举行。本次会议论文收录工作已经结束,金山云金睛算法团队与合作高校联名发表的三篇论文被大会收录。

CVPR作为行业最顶级的研究型会议,每年收录的论文均来自计算机视觉领域顶级团队,代表着国际最前沿的科研技术,并指引着计算机视觉领域未来的研究方向。今年收录的论文,主要涵盖深度学习优化原理、视觉对抗学习、人脸建模与识别、视频深度理解、行人重识别、人脸检测等热门及前沿技术领域。
金山云金睛算法团队与合作高校联名发表的三篇论文,对神经网络训练中的监督方式进行了深入的探讨,涵盖教师-学生模型监督方式、自监督学习、大规模X光机彩色图片的弱监督学习开发三个方面。此次论文被CVPR收录,代表着金山云金睛在神经网络监督学习领域已达到国际一流水平。
“金睛”基于金山云强大的云计算基础资源能力和海量数据积累,专注于图像识别、语音识别、多模态视频分析、文本识别、人脸识别、行人车辆识别等人工智能领域的研究,提供跨行业、多场景的AI解决方案。目前,金山云金睛算法团队已经与中国科学院大学模式识别与智能系统开发实验室、中国科学院自动化研究所模式识别重点实验室、中国科学院计算技术研究所智能信息处理重点实验室、中山大学数据科学与计算机学院等多个全球顶级人工智能实验室建立了长期的战略合作关系。“金睛”稳定的高精尖研发团队、丰富的产品运营经验为金山云AI服务提供了充足的技术保证和发展动能。
附:金山云金睛入选CVPR2019的论文节选:
“Snapshot Distillation: Teacher-Student Optimization in One Generation”
《快照蒸馏:单模型训练下完成教师-学生优化》
本文介绍了第一种能够在训练单个模型的条件下完成教师-学生优化的方法——快照蒸馏(Snapshot Distillation)。该方法的核心环节十分直观:在单个模型的训练过程中,我们从早期样本遍历后的模型(教师模型) 提取有用信息对后期遍历中的模型(学生模型) 进行监督训练。与此同时,该方法保证教师和学生模型的神经网络差异性,来防止欠拟合问题的发生。在实现快照蒸馏算法时,我们采用余弦函数学习率,将整个训练过程分为若干周期,在每一周期结束时提取模型快照(snapshot),并在新的周期迭代中用其提供监督信息。模型快照作为教师模型,其输出信息被模糊化处理以提供有益监督。在基本的图像分类数据集上,例如CIFAR100和ILSVRC2012,快照蒸馏在不引入过多的计算消耗情况下,实现了持续的性能提升。此外,我们通过Pascal VOC上的转换实验,验证了经过快照蒸馏预训练的模型,同样可以提高其在对象检测和语义分割任务中的性能。
“Iterative Reorganization with Weak Spatial Constraints: Solving Arbitrary Jigsaw Puzzles for Unsupervised Representation Learning”
《基于求解任意拼图问题的自监督学习方法》

本文提出一种适用于任意网格尺寸与维度的“拼图”问题的新方法,同时提出了一个基本且具有普遍意义的原则,即在无监督场景中较弱的信息更容易被学习,且具有更好的可迁移性。对于“拼图”问题,本文以迭代的方式逐步调整图像块的顺序直到收敛,而不试图一步解决。每一步都通过组合图像块中抽取的一元和二元特征,得到表示当前布局正确性的代价函数。通过考虑布局之间的联系,本文方法以更合理的方式学习视觉信息。其有效性可从两方面得到验证。首先,它能够解决现有方法难以处理的任意网格尺寸与维度的“拼图”问题,包括高维“拼图”问题。第二,它提供一种可靠的网络初始化方法,帮助图像分类、目标检测和语义分割等视觉识别任务取得更好的性能。
“SIXray: A Large-scale Security Inspection X-ray Benchmark for Prohibited Item Discovery in Overlapping Images ”(此文由中国科学院大学模式识别与智能系统开发实验室与金山云联名发表)
《SIXray : 大规模X光违禁品安检数据集》
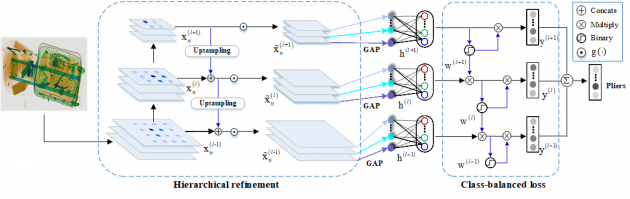
本文针对X光安检数据集,提出了类别均衡的分层细化模型处理数据集存在的问题。该模型假设每个输入图片都是从混合分布中采样得到的,而深层网络需要一个迭代过程来精确地推断图像内容。我们将反向连接插入到不同的网络骨干中,用高层的视觉线索辅助中间层的特征学习。除此之外,针对数据集正反例样本不均衡的特点,设计了一个类平衡损失函数,最大限度地减少了简单负样本产生的噪声。
(免责声明:本文为企业宣传商业资讯,仅供用户参考,如用户将之作为消费行为参考,凤凰网敬告用户需审慎决定。)

[责任编辑:于新陆 PN175]
责任编辑:于新陆 PN175
- 好文

- 钦佩

- 喜欢

- 泪奔

- 可爱

- 思考

为您推荐






































热门文章
-

东三环世界格局,邦泰集团匠心钜筑礼献成都
-

锚定“新经济+大资管”中期战略,德邦证券未来发展新格局
-

凤凰网刘爽:算法推送短视频时代的冷思考
-

做对外贸易今后好做吗?对外国际外贸平台行业前景分析!
-

凤凰网池小燕:挖掘媒体平台新价值 驱动企业利润新增长
-

价值驱动新增长 营销凝聚新共识 ——万象更新·凤凰网2021营销趋势大会在京召开
-

明君集团徐明君二十余载追求卓越、不断创新
-

中港置业被评为“锦江区百强民营企业”!
-

汉德森公益广告亮相上海中心地铁站,其产品在汉薇商城有售!
-

邓伦火锅店背后故事首度揭秘,没想到店如其人!
-

安全事故无小事,龙元建设安全生产的行动派
-

《2020中国互联网广告数据报告》正式发布
精彩视频












凤凰网商业官方微信




